

Est-ce que tu savais que Disney avait recyclé pendant des années ses meilleures animations dans plusieurs de ses dessins animés populaires ? Ce que je te propose dans ce tutoriel, c’est de faire la même chose avec tes propres vidéo et l’outil en ligne GEN-1 de Runway ML.
Pourquoi Disney recyclait ses meilleures animations ?
Le Livre de la Jungle, Winnie L’ourson, Les 101 Dalmatiens, Merlin l’enchanteur, Robin des bois, Dumbo, Bambi, Blanche Neige, Alice aux Pays des merveilles, la liste est trop grande pour que je te cite tous les films.
Une même animation réalisée pour un film servait souvent à plusieurs films. On retouchait juste le personnage, par exemple Christopher à la place de Mowgli, mais le mouvement restait le même.
Cela permettait de faire des économies dans la production très coûteuse d’animations.
La Rotoscopie aussi utilisée par Disney
En fait, Disney allait même jusqu’à filmer en amont des scènes de vrais gens en mouvement pour les recréer ensuite en dessin animé. On appelle ce procédé cinématographique très efficace : la rotoscopie.
Il y a d’ailleurs un célèbre clip de A-ha “Take on me” qui a appliqué cet effet à tous les personnages de la vidéo les transformant ainsi en personnages animés de BD.
Cela te dirait de faire la même chose avec tes propres photos ou vidéos ? Bonne nouvelle ! On peut faire cela nous même très facilement sans bosser chez Disney ou chez Warner, grâce à l’intelligence artificielle de GEN-1.
Comment fonctionne Gen-1 de Runway ML ?
Voici un extrait du papier de Recherche : Structure and Content-Guided Video Synthesis with Diffusion Models

TL;DR : GEN-1 de RunWay ML réussit à générer une rotoscopie satisfaisante et peu coûteuse en s’appuyant sur quelques images clés de la vidéo et en gardant constant les paramètres du modèle de diffusion choisi.
Les modèles de diffusion générative guidés par le texte permettent de créer et de modifier des images puissantes. Bien que ces modèles aient été étendus à la génération de vidéos, les approches actuelles pour éditer le contenu des vidéos existantes tout en conservant leur structure nécessitent un ré-entraînement coûteux pour chaque entrée ou s’appuient sur une propagation d’éditions d’images entre les images sujette aux erreurs. Dans ce travail, nous présentons un modèle de diffusion vidéo guidé par la structure et le contenu qui permet d’éditer des vidéos en fonction de descriptions visuelles ou textuelles de la sortie souhaitée. Notre modèle est entraîné conjointement sur des images et des vidéos, ce qui permet également un contrôle explicite de la cohérence temporelle grâce à une nouvelle méthode de guidage.
C’est quoi Runway ML ?
Runway ML (ML = Machine Learning) est une plateforme d’apprentissage automatique et d’intelligence artificielle qui permet aux créateurs, artistes, designers et développeurs d’accéder facilement à des modèles de machine learning avancés et de les intégrer dans leurs projets.
Cette plateforme est conçue pour rendre l’intelligence artificielle plus accessible et simplifier le processus de création pour les non-experts en la matière.
Les utilisateurs peuvent explorer, adapter et utiliser une variété de modèles pré-entraînés pour des applications telles que la génération d’images, de vidéos, la reconnaissance d’objets, la traduction de texte, etc.
Tous cette suite d’outils (AI Tools) est accessible ici en se créant un compte via un modèle freemium : https://app.runwayml.com/ai-tools
Gen-1 : Comment transformer une vidéo en dessin animé ?
Runway ML donne quelques conseils de configuration sur cette vidéo
Et sur son Twitter ici
On doit d’abord uploader une vidéo de moins de 5 secondes ici. Et ensuite indiquer à Gen-1 comment reconstruire la vidéo à l’aide d’une image, de réglages prédéfinis ou d’un prompt.
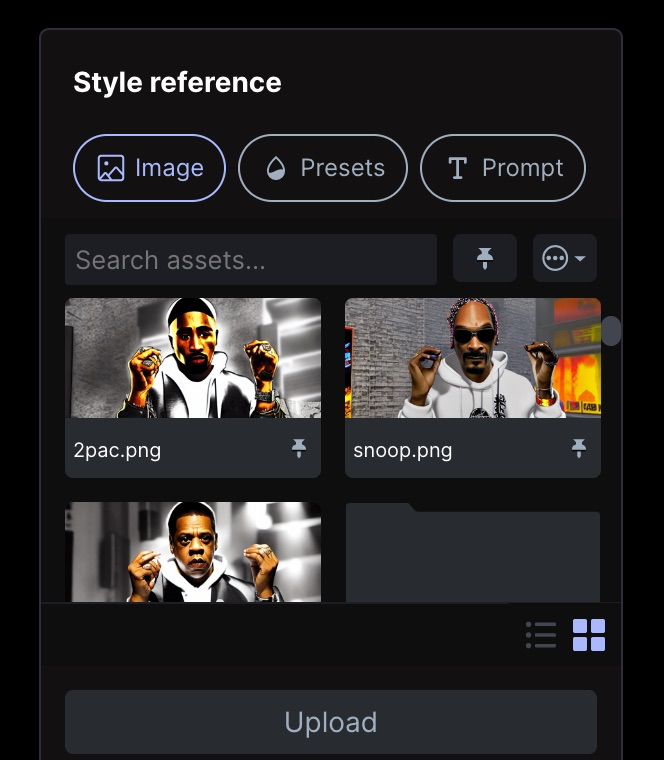
L’ajout d’une image de référence donne de meilleurs résultats. Soit vous trouvez sur le net une image (option 1) qui vous inspire et qui ressemble à votre image source, comme je l’ai fait ici avec mon but.
Soit vous utilisez le projet HuggingFace ControlNet (Filtre HED) pour générer avec un prompt à partir d’une de vos images clés en quoi vous souhaitez vous transformer (option 2).
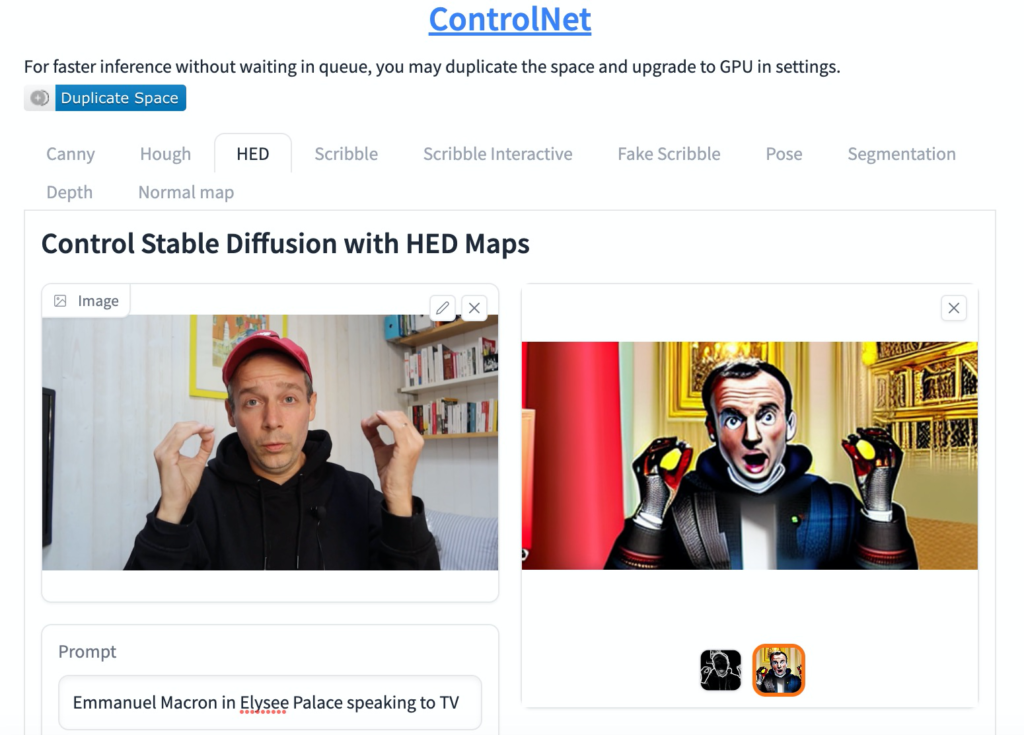
Perdu avec ControlNet et Hugging Face ? J’en parle dans cette vidéo ControlNet.
Ensuite, il faut jouer un peu sur les réglages avancés de Gen-1. Si vous avez choisi l’option 1, ces réglages marchent bien :
- Structural consistency : 2
- Weight : 8.5
- Frame : 1.2
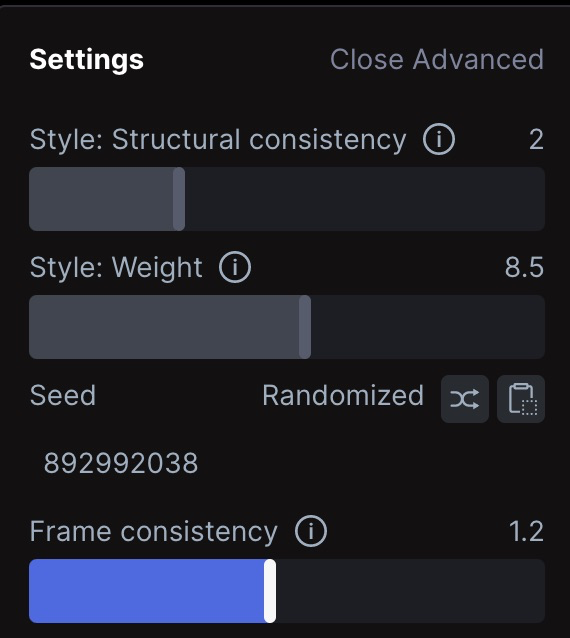
Si vous avez choisi l’option 2 (avec ControlNet), mettez 0 au lieu de 2 dans structural consistency et 6 à weight. Quand vos réglages sont bons, cliquez sur Generate et patientez 2-3 minutes.
Voilà le rendu avec les visages de Jay-Z, Snoop Dogg, 2 Pac, Notorious B.I.G (option 2)
On peut aussi utiliser un prompt directement dans GEN-1 Runway ML
Et voici une autre façon de générer une animation avec un prompt directement dans l’outil Runway ML.
Et toi, en quoi vas-tu te transformer ? 😉